04.6.6.1 uform-gen2-qwen-500m (preview)
Node Description
uform-gen2-qwen-500m (preview) - action type node needed to generate text from an image.
Model ID: @cf/unum/uform-gen2-qwen-500m. Designed primarily for image captions and visual question answering. The model was pre-trained on an internal image captioning dataset and refined on publicly available instruction datasets: SVIT, LVIS, and VQAs datasets.
Image to Text technology is widely used in a variety of applications where textual information needs to be extracted from visual sources to automate, increase efficiency, and improve accessibility. Examples of use cases:
- Document digitization: converting paper documents such as books, journals, invoices and forms into editable text format for further processing, archiving and retrieval.
- Data Entry Automation: extracting text from images to automatically populate forms, spreadsheets or databases, saving time and reducing the likelihood of manual entry errors.
- Accessibility for people with disabilities: convert text from images to speech or text to read aloud, helping people with visual impairments or other disabilities.
- Search and indexing: extract text from images and index it to make it easier to find and navigate large sets of documents.
- Analytics and Intelligence: extracting key information such as addresses, phone numbers, dates, etc. from images for further analysis and decision making.
- Translation: converting text from images in one language to another to facilitate cross-lingual communication.
Node Configuration
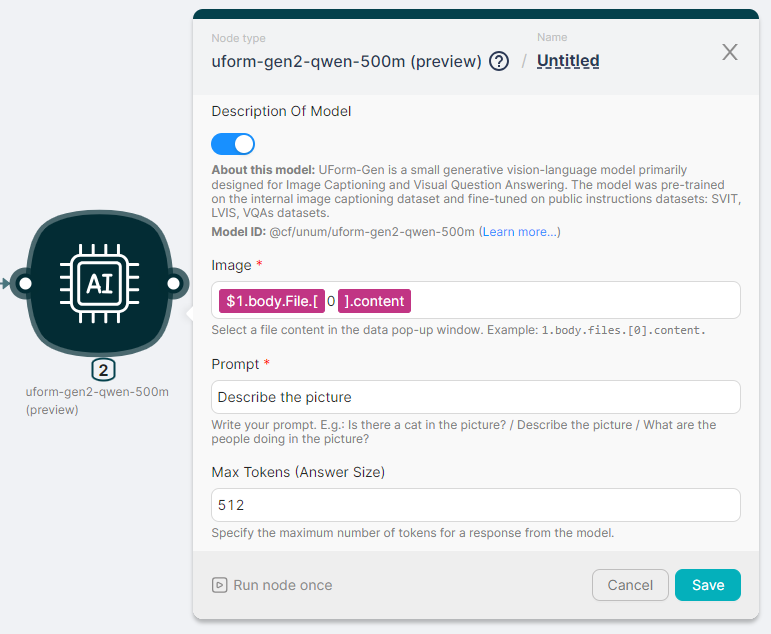
Required and optional fields are required to configure the uform-gen2-qwen-500m (preview) node. Required fields include:
- Image;
- Prompt.
Image
Field for entering image file content in the format 1.body.files.[0].content.
Content is one of the output parameters of nodes that work with files. A file can also be transferred to the Trigger on Webhook node address.
Prompt
A text field to enter a query to AI to generate a response based on the image content.
Max Tokens (Answer Size)
The maximum number of response tokens that can be generated by AI before stopping. Models can stop before reaching this maximum. This parameter sets only the absolute maximum number of tokens that can be generated.
Example of launching a node
To obtain the image description, we add two nodes to the scenario:
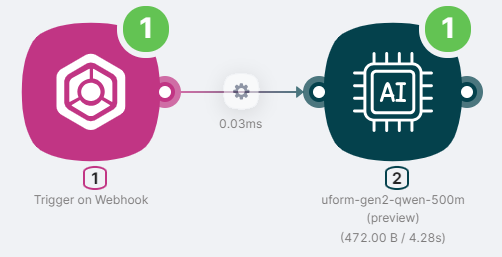
- Trigger on Webhook node to run the scenario and transfer the file to the scenario;
- The uform-gen2-qwen-500m (preview) node to process image content and generate a response.
The output of the scenario is JSON:
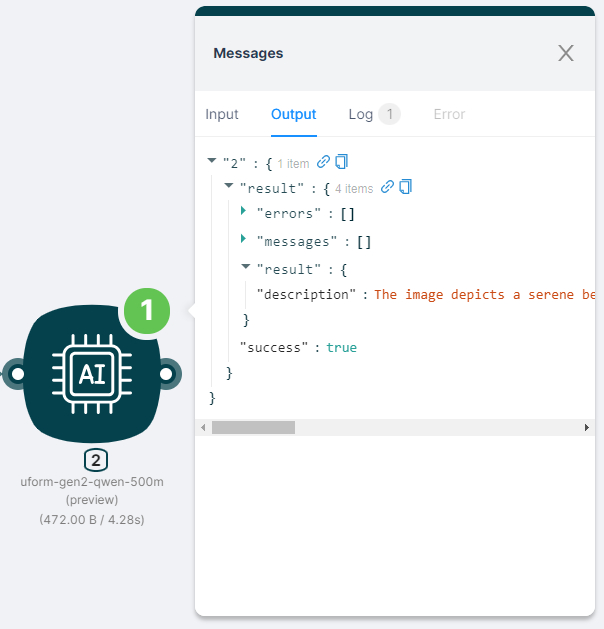
- with a response to an AI request, such as an image description;
- with the action execution status
"success": true.
JSON
{
"result": {
"errors": [],
"messages": [],
"result": {
"description": "The image depicts a serene beach scene. Two wooden lounge chairs are placed on the sandy beach, facing the ocean. The chairs are positioned under a tall palm tree, which is situated on the left side of the image. The ocean is a beautiful shade of blue, with small waves gently lapping against the shore. The sky above is a clear blue with a few clouds scattered across it."
},
"success": true
}
}