04.6.13.10 llamaguard-7b-awq
Model Description
The @hf/thebloke/llamaguard-7b-awq model includes two nodes:
- llamaguard-7b-awq Prompt (preview)
- llamaguard-7b-awq With History (preview)
Model ID: @hf/thebloke/llamaguard-7b-awq. Llama Guard is a model for classifying the security of LLM prompts and responses using the security risk taxonomy.
Llama Guard is a model that helps determine how secure queries and responses are in large text datasets. It uses a special system called a "security risk taxonomy" to determine the level of danger to the information. For example, it can help determine if the text contains any threats, insults, or other potentially harmful elements. This can be useful, for example, for filtering content on social networks or detecting malicious messages in chat rooms.
Example of launching a node
A description of the node fields can be found here.
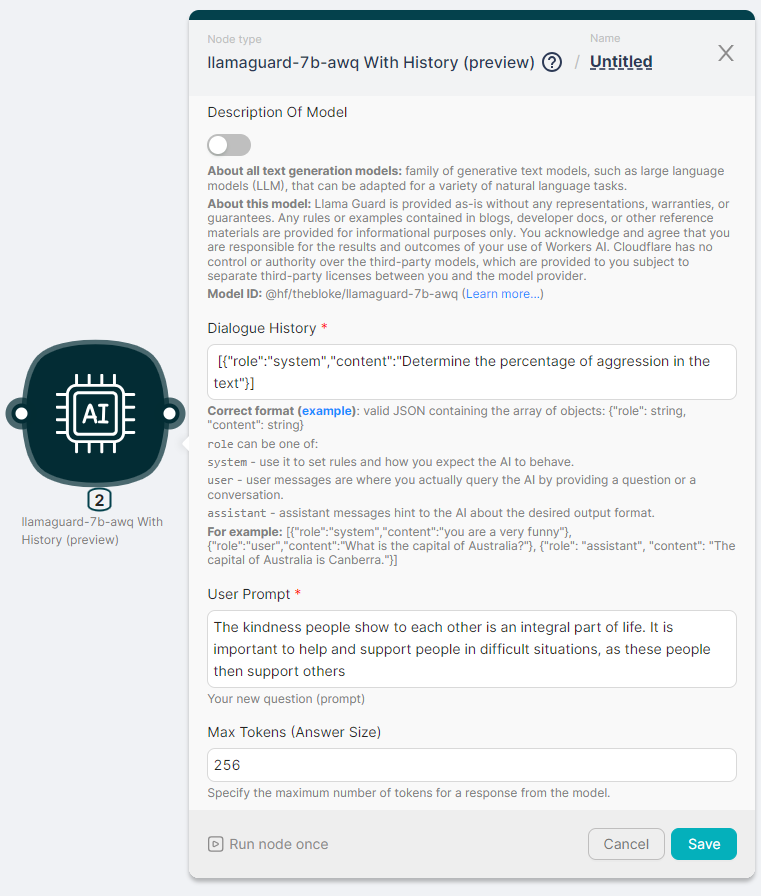
Let's run the llamaguard-7b-awq With History (preview) node to process the text and generate a response with parameters:
- Dialogue History -
[{"role":"system","content":"Determine the percentage of aggression in the text"}];
- User Prompt - The kindness people show to each other is an integral part of life. It is important to help and support people in difficult situations, as these people then support others;
- Max Tokens (Answer Size) - 256.
The output of the node execution is JSON:
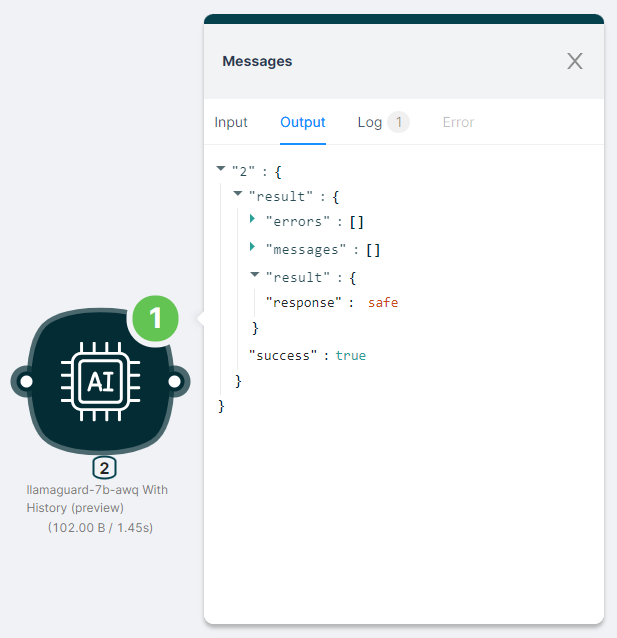
- with a response to the
"response"request;
- with the status of the action
"success": true.
JSON
{
"result": {
"errors": [],
"messages": [],
"result": {
"response": " safe"
},
"success": true
}
}