04.6.13.08 llama-2-7b-chat-fp16
Model Description
The @cf/meta/llama-2-7b-chat-fp16 model includes two nodes:
- llama-2-7b-chat-fp16 Prompt (preview)
- llama-2-7b-chat-fp16 With History (preview)
Model ID: @cf/meta/llama-2-7b-chat-fp16. Generative text model with full precision (fp16) and 7 billion parameters from Meta.
Maximum number of input tokens: 3072. Output sizes: 2500
The model is trained specifically for tasks in the field of chatbots and dialog systems. The main features and applications of this model are:
- Training on large dialog data: The model has been trained on large dialog datasets, which allows it to better understand and generate natural dialog content.
- Optimization for Dialog Systems: The model has been specifically optimized for interactive dialog systems, allowing it to support two-way dialogs more efficiently and naturally.
- Smaller size for faster performance: The model has a relatively smaller size (2.7 billion parameters) than some other large language modelers. This allows it to run faster and more efficiently, which is important for dialog systems.
- Support for FP16 computing architecture: The model is optimized to work with FP16, which allows for faster model output on suitable hardware.
This model can be used to build dialog agents, chatbots, question-answer systems, and other interactive applications where a natural dialog interface is required.
Example of launching a node
A description of the node fields can be found here.
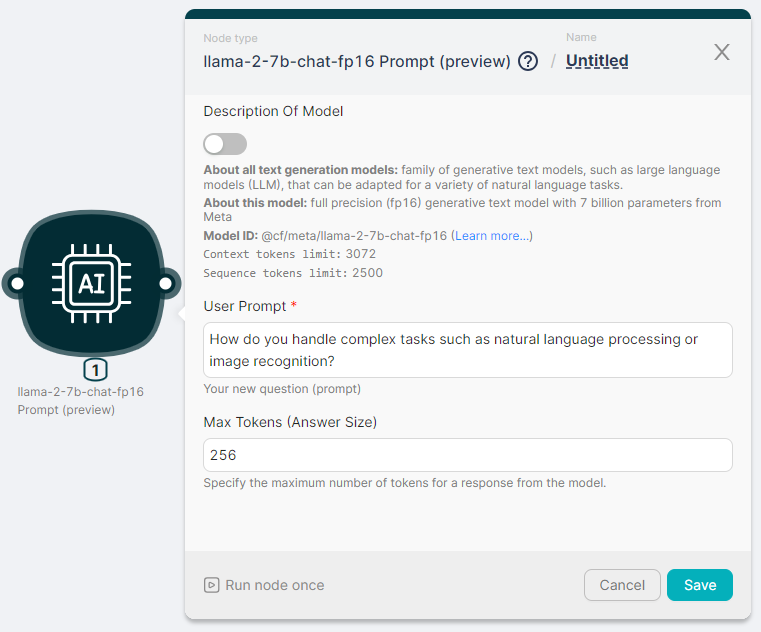
Let's run the llama-2-7b-chat-fp16 Prompt (preview) node to process the text and generate a response with parameters:
- User Prompt - How do you handle complex tasks such as natural language processing or image recognition?
- Max Tokens (Answer Size) - 256.
The output of the node execution is JSON:
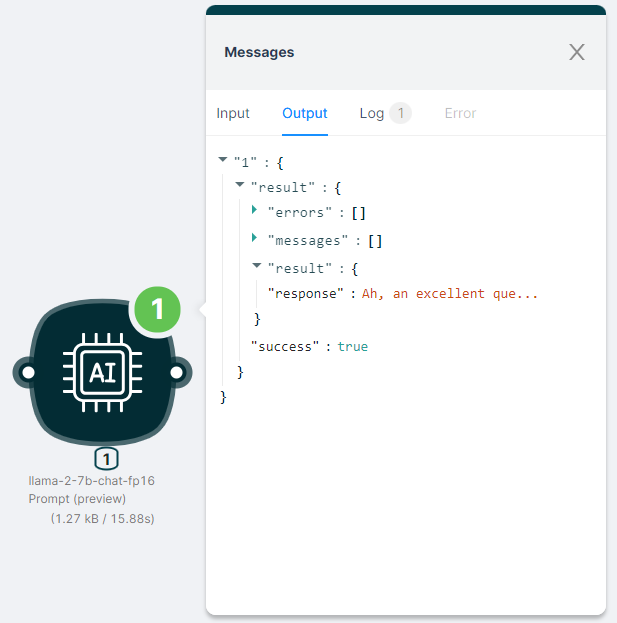
- with a response to the
"response"request;
- with the status of the action
"success": true.
JSON
{
"result": {
"errors": [],
"messages": [],
"result": {
"response": "Ah, an excellent question! *adjusts glasses*\n\nAs an AI assistant, I have been trained on a vast array of tasks, including natural language processing (NLP) and image recognition. These are complex tasks that require a deep understanding of language and visual patterns, respectively.\nTo handle these tasks, I employ a combination of machine learning algorithms and large-scale data sets. For NLP, I have been trained on a vast corpus of text data, which allows me to recognize patterns in language and generate coherent and contextually appropriate responses.\nSimilarly, for image recognition, I have been trained on a vast dataset of images, which enables me to identify objects, scenes, and actions within images. This training allows me to recognize and classify images with a high degree of accuracy.\nHowever, it's important to note that these tasks are not solely the realm of AI. Human intelligence and creativity are still essential for tasks that require a deep understanding of context, nuance, and ethical considerations.\nFor example, when it comes to NLP, while I can generate text that is grammatically correct and contextually appropriate, I may not always be able to understand the"
},
"success": true
}
}