04.6.2.15 Vision

Node Description
Vision is an action type node is required to send an image and accompanying text to ChatGPT to generate a response regardless of assistants, threads and runs.
Node Configuration
To configure the Vision node, you must fill in the required and optional fields.
The required* fields include:
- API Key.
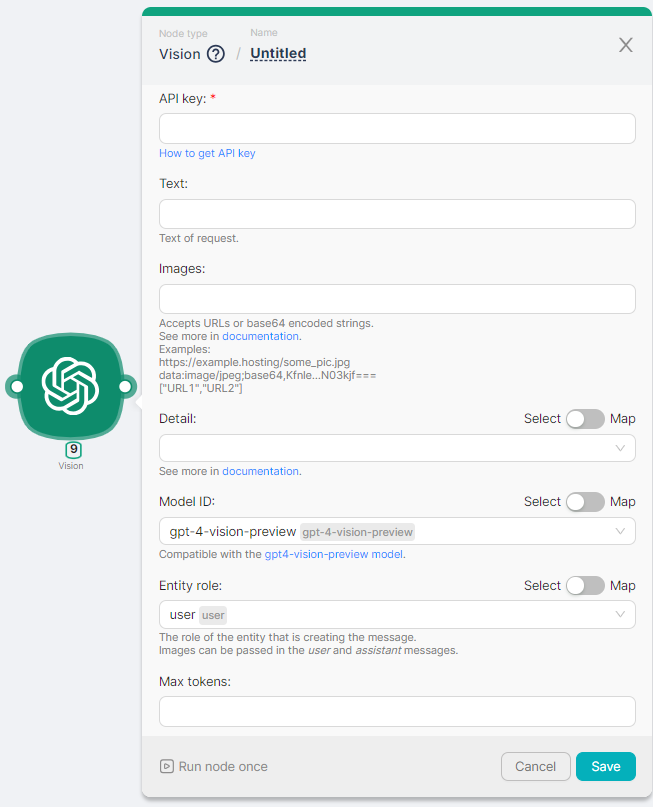
API Key
The field required for entering the API key (see more details here).
Text
The text of the question on the image or images.
Images
The image is in URLs or base64 encoded string format. See more here.
Detail
By controlling the detail parameter, which has three options, low, high, or auto, you have control over how the model processes the image and generates its textual understanding. By default, the model will use the auto setting which will look at the image input size and decide if it should use the low or high setting.
- low will disable the “high res” model. The model will receive a low-res 512px x 512px version of the image. This allows the to return faster responses and consume fewer input tokens for use cases that do not require high detail.
- high will enable “high res” mode, which first allows the model to see the low res image and then creates detailed crops of input images as 512px squares based on the input image size.
See more here.
Model ID
Drop-down list to select the desired version of the GPT Chatbot model (see more details here). By default, the field is filled with the value gpt-4-vision-preview.
Entity role
The role of the entity that is creating the message. The user value or the assistant value can be selected.
Max tokens
See more here.
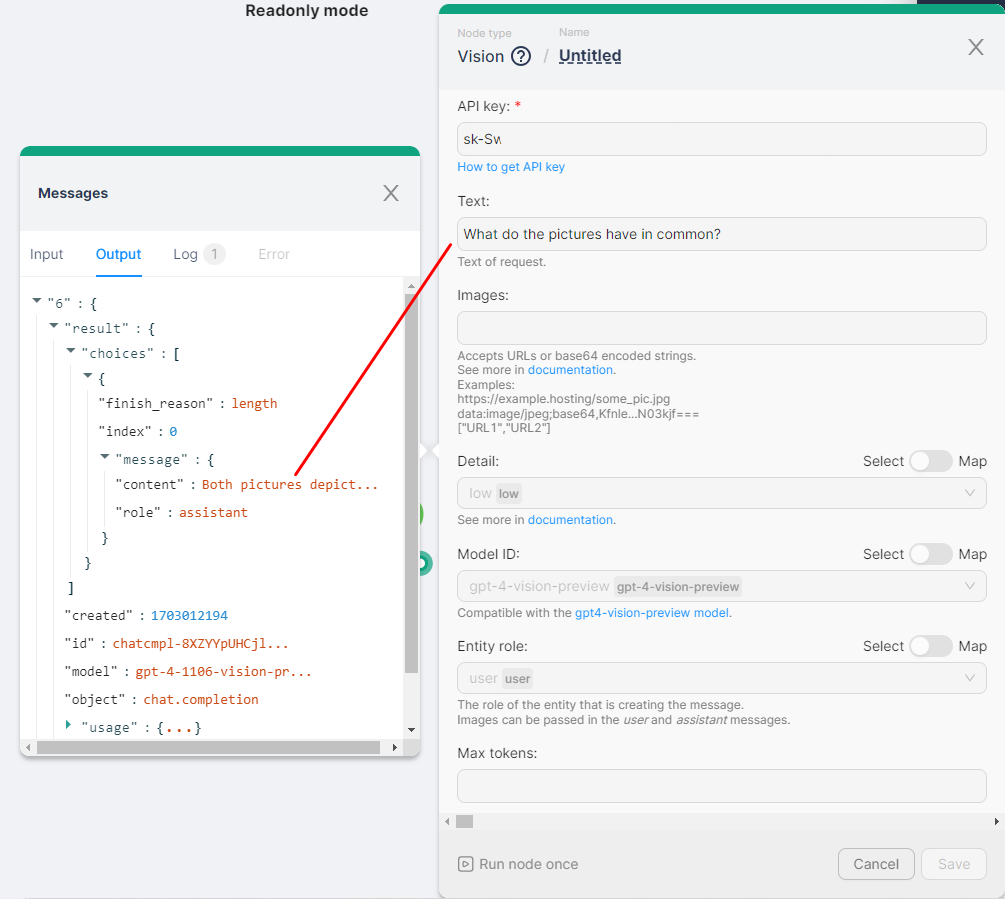
Example of launching a node
It is necessary to run the node Vision once with the parameters:
- API Key - Your API key;
- Text - What do the pictures have in common?;
- Images - The image is in base64 encoded string format;
- Detail - low;
- Model ID - gpt-4-vision-preview;
- Entity role - user.
The result of the Vision node execution is to get an answer to the question about the images: